
EAX – dźwięk przestrzenny w Windows 9x/XP.
EAX ( Environmental Audio Extensions ) – Standard dźwięku przestrzennego opracowany w 1998 roku przez firmę CreativeLabs. Rozwiązania sprzętowe i programowe mające zapewnić wrażenie realistycznego dźwięku wielokanałowego, głównie w grach. EAX miał sprzętową obsługę w w systemach Windows rodziny 9x, Windows XP oraz Vista. Przestał być wspierany wraz z premierą Windows 7, a jego elementy zostały „wchłonięte” przez Microsoft jako część DirectSound3d.
Historię i rozwój standardu EAX przybliża artykuł opublikowany na stronie benchmark.pl , z dnia 31 lipca 2005 roku. Tłumaczenie dla serwisu benchmark.pl przez grupę translatornia.pl
https://www.benchmark.pl/testy_i_recenzje/creative-x-fi-technologia-dzwieku-3d.html
Zapraszam do lektury.
Creative X-Fi: Technologia dźwięku 3D
Omówienie nowej generacji technologii CMSS i EAX dla dźwięku 3D oraz surround w grach, muzyce i filmach.
Dr. Jean-Marc Jot kierownik naukowców dźwięku 3D, Ośrodka Technologii Zaawansowanej firmy Creative.
Nieco historii
Dawno temu, w roku 1998, wraz z kartą Sound Blaster Live!, firma Creative przedstawiła pierwszy sprzętowy akcelerator dźwięku 3D zdolny do odtwarzania dźwięku dookólnego na pecetach stacjonarnych. Własnej produkcji układ DSP, który napędza kartę Sound Blaster Live!, był również pierwszym procesorem w swojej klasie, wyposażonym w programowalny silnik DSP zdolny do obsługi takich algorytmów efektowych, jak pogłos, chorus czy przesuwnik wysokości tonu. Na tej nowej platformie firma Creative wypuściła nowe technologie: EAX oraz CMSS (Creative Multi-Speaker Surround – wielogłośnikowy dźwięk dookólny), co umożliwiło grom PC zaoferowanie lepszego złudzenia zanurzenia w dźwięku dookólnym za pomocą realistycznych sygnałów pogłosowych. Przez kolejne dwa lata, z pomocą karty Live! i mikroukładu EMU10K1, firma Creative umocniła EAX 1.0 oraz EAX 2.0 na pozycji prawdziwych standardów branżowych, a CMSS rozszerzyła z 4-kanałowego na 5.1.
Wraz z nadejściem procesora Audigy, wydanego w roku 2001, firma Creative wprowadziła obsługę głośników 6.1 i zwiększyła wydajność programowalnego silnika DSP, aby umożliwić obsługę bardziej zaawansowanych efektów pogłosu (EAX 3.0) oraz ulepszeń trójwymiarowego dźwięku pozycyjnego. W następnych latach platforma Audigy była dalej rozszerzana zapewniając ostatecznie obsługę wielokanałowego formatu 7.1 i rendering wielu środowisk jednocześnie. Aktualizacja sterownika EAX 4.0 ADVANCED HD wydanej w listopadzie 2003 roku umożliwiła karcie Audigy obsługę maksymalnie trzech procesów pogłosu środowiskowego jednocześnie.
Dźwięk trójwymiarowy X-Fi
Wraz z kartą X-Fi firma Creative przedstawia nowy, przełomowy procesor dźwięku, który jest bez porównania mocniejszy i bardziej elastyczny niż którykolwiek z poprzednich układów firmy Creative, czy jakikolwiek istniejący procesor dźwięku w tej klasie. Do możliwości X-Fi zaliczyć można bezkompromisową dokładność trójwymiarowego dźwięku pozycyjnego z setek źródeł dźwięku 3D, zaawansowane algorytmy przetwarzania częstotliwości sygnału, obsługę danych dźwiękowych wysokiej rozdzielczości (próbki 24-bitowe przy częstotliwościach próbkowania dochodzących do 192, a nawet 384 kHz!) oraz obsługę praktycznie nieograniczonej elastyczności w budowie sieci przetwarzania sygnałów dźwiękowych.

Równolegle do owej ewolucji w technologii sprzętu DSP, której kulminację stanowi dziś platforma X-Fi, firma Creative buduje wyjątkowy wachlarz własności intelektualnej w dziedzinie dźwięku 3D poprzez nieustanne rozwijanie i doskonalenie technologii EAX i CMSS. Oprócz wewnętrznego rozwoju własności intelektualnej, firma Creative wykorzystuje również własność intelektualną pozyskaną w wyniku nabycia firmy Aureal (w roku 2000), a ostatnio firmy Sensaura (2003). W tym samym okresie firma Creative utworzyła spółki i licencje technologiczne z czołowymi instytucjami badań dźwięku 3D, jak np. Laboratorium akustyki pomieszczeń – Room Acoustics Laboratory przy IRCAM (w Paryżu) oraz z Uniwersytetem Kalifornijskim w Davis. Dzięki temu firma Creative posiada aktualnie jeden z najszerszych wachlarzy patentów dźwięku trójwymiarowego i zatrudnia jeden z najlepiej wykwalifikowanych zespołów naukowców i inżynierów dźwięku trójwymiarowego w branży (w tym 6 doktorów nauk o specjalizacjach podyplomowych w dziedzinie dźwięku 3D, co daje razem ponad 70-letnie doświadczenie podyplomowe i/lub branżowe na tym polu).
Platforma X-Fi jest zaprojektowana w sposób zapewniający moc i elastyczność przetwarzania konieczne do tego, by Creative mogła znaleźć przełożenie na praktykę dla swojej szerokiej IP oraz wiedzy z dziedziny dźwięku 3D i przetwarzania efektów dźwiękowych.
W związku z tym firma wprowadzi wraz z X-Fi nową generację technologii CMSS-3D, oferując nowy poziom przyjemności odsłuchu i wydajności poprzez takie dostosowanie doznania odsłuchowego, które w pełni wykorzysta aparat słuchu w każdym z zastosowań:
CMSS-3DSurround – wielokanałowy dźwięk dookólny z nagrań dookólnych,
CMSS-3DVirtual – rendering opływającego dźwięku 3D za pomocą dwóch głośników,
CMSS-3DHeadphone – rendering opływającego dźwięku 3D za pomocą słuchawek,
CMSS-3DInteractive – interaktywny pozycyjny dźwięk 3D dla kilku źródeł jednocześnie.
Na kolejnych stronach szczegółowo przeanalizujemy wyjątkowe właściwości tych technologii i to, w jaki sposób łączą się one w X-Fi, optymalizując przestrzenną prezentację dźwiękową w dowolnej konfiguracji odsłuchu przez słuchawki czy głośniki, oraz w różnych sceneriach użycia.
Odkryjemy również, w jaki sposób rozwinął się silnik przetwarzający dźwięk EAX firmy Creative, stając się uniwersalną architekturą do obróbki dźwięku trójwymiarowego i efektów, która obejmuje szeroką gamę komputerowych zastosowań dźwiękowych, m.in.:
-dźwięk interaktywny do gier, multimediów lub rzeczywistości wirtualnej,
-rozrywkowe odtwarzanie muzyki i filmów,
-tworzenie i nagrywanie muzyki na kilku kanałach.
Krótki przegląd technologii dźwięku trójwymiarowego firmy Creative
Firma Creative opracowała swój własny wszechstronny zestaw technologii obróbki dźwięku, aby zapewnić fascynujące odczucia zanurzenia podczas odsłuchu we wszystkich komputerowych zastosowaniach dźwiękowych. Aby różnego rodzaju treści dźwiękowe mogły wykorzystać owe technologie, konieczne są również odpowiednie interfejsy programów użytkowych (API) do odtwarzania dźwięku. Wychodząc naprzeciw tej potrzebie, firma Creative opracowała i czynnie wspiera kilka otwartych i własnych standardów dostarczania i redagowania trójwymiarowych treści dźwiękowych.
Krótki przegląd technologii dźwięku trójwymiarowego firmy Creative:
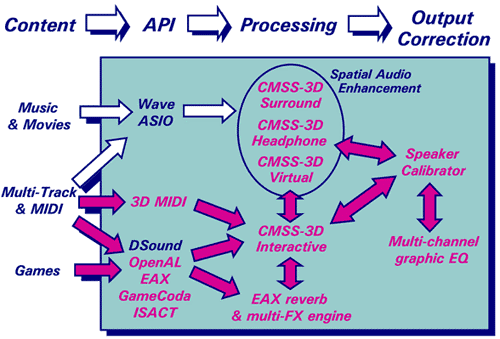
Technologie obróbki dźwięku trójwymiarowego i dookólnego firmy Creative widać po prawej stronie ilustracji 1. Można je podzielić na trzy grupy:
Wzbogacanie dźwięku przestrzennego
Własne technologie optymalizacji doznania odsłuchowego dla wszystkich dwukanałowych lub wielokanałowych formatów poprzez różne formaty odtwarzania (CMSS-3DHeadphone, CMSS-3DVirtual, CMSS-3DSurround).
Rendering interaktywnego dźwięku 3D
Własne technologie uprzestrzenniania dźwięków w dowolnym miejscu przestrzeni trójwymiarowej, statycznych lub ruchomych, wraz z udoskonaleniami konstrukcji dźwięku i efektami środowiskowymi (CMSS-3DInteractive, pogłos EAX oraz silnik multi-efektów.).
Korekcja sygnału wyjściowego
Kalibrator głośników oraz wielokanałowy korektor graficzny firmy Creative optymalizują odtwarzanie przestrzennej scenerii dźwiękowej zapewniając korekcję charakterystyki częstotliwościowej oraz wyrównywanie czasowe kanałów wyjściowych. Kalibrator głośników komunikuje się również z silnikiem renderingu CMSS-3Dinteractive, zapewniając „kalibrację kątową”, która pozwala uniknąć zniekształceń sceny dźwiękowej, które bez nich miałyby miejsce w przypadku niestandardowego umiejscowienia głośników w pomieszczeniu odsłuchowym.
Więcej szczegółów na temat nowej generacji technologii wzbogacania dźwięku przestrzennego oraz interaktywnego dźwięku 3D firmy Creative znaleźć można w dalszej części prezentacji.
Standardy interaktywnego dźwięku 3D
Dźwiękowy interfejs programów użytkowych (API), to zbiór rozkazów, które program komputerowy może wykorzystywać do wyzwalania lub odtwarzania dźwięków oraz dodawania do nich efektów dźwiękowych. Platforma Windows firmy Microsoft zawiera interfejs API DirectSound do interaktywnych zastosowań dźwiękowych (jak np. gry), oraz interfejs API Wave do standardowego odtwarzania dźwięku. Interfejs ASIO firmy Steinberg to API alternatywne wobec Wave, zoptymalizowane dla potrzeb narzędzi programowych służących do tworzenia muzyki.
Firma Creative opracowuje lub prowadzi opracowanie szeregu nowych interfejsów API i formatów (zaznaczonych na czerwono po lewej stronie ilustracji 1), aby umożliwić międzyplatformowe stosowanie wielokanałowych gier lub treści dźwiękowych wykorzystujących w pełni dzisiejsze wielokanałowe systemy odtwarzania oraz technologie dźwięku 3D.
Międzyplatformowe interfejsy API do renderingu interaktywnego dźwięku 3D (OpenAL, GameCoda, EAX).
Firma Creative jest jedną z głównych sił napędowych odpowiedzialnych za opracowanie interfejsu OpenAL, który udostępnia typowe funkcje dźwięku 3D w szerokim przedziale platform do gry (m.in. Windows, Mac, Linux oraz konsole do gier). GameCoda to własny interfejs API opracowany przez firmę Sensaura, zapewniający gładką integrację zaawansowanych efektów dźwiękowych wraz z narzędziami programowo-sprzętowymi, ułatwiający opracowywanie gier na platformy konsolowe (Xbox, PlayStation oraz GameCube). EAX to rozszerzenie API dla DirectSound, OpenAL oraz GameCODA, zapewniające zaawansowane efekty audio dźwiękowe wzbogacające realizm i konstrukcję dźwięku w interaktywnych zastosowaniach dźwiękowych.
Formaty kompozycji interaktywnego dźwięku 3D (SACT oraz 3DMIDI).
Tworzenie muzyki wielokanałowej oraz pejzaży dźwiękowej wymaga zazwyczaj narzędzi studyjnych do rozpisywania parametrów miksu wielokanałowego, w tym parametrów uprzestrzennienia i obróbki efektów oddzielnie dla każdej ze ścieżek. Firma Creative opracowała technologie umożliwiające dostarczenie takiego rozpisanego na wiele kanałów miksu wprost do odbiorcy, bez potrzeby uprzedniego „zgrywania” do konkretnego formatu, np. 5.1 czy stereo dwukanałowego.
ISACT to skrót od Interactive Spatial Audio Composition Tool (Narzędzie do kompozycji interaktywnego dźwięku przestrzennego).
Jest to interfejs API, format treści oraz narzędzie redakcyjne wysokiego poziomu do tworzenia oraz dostarczania wielokanałowej muzyki i ścieżek dźwiękowych. Format ISACT zawiera deskryptory wysokiego poziomu, umożliwiające autorowi nadawanie zmienności muzyce lub ścieżce dźwiękowej, aby brzmiały one inaczej przy każdym odtworzeniu, reagowały na oddziaływanie słuchacza albo sygnał zewnętrzny, lub grały bez końca nie powtarzając się – cały czas brzmiąc tak gładko, jak nagranie ciągłe.
3DMIDI to rozszerzenie popularnego standardu MIDI służącego do sterowania programowymi i sprzętowymi syntezatorami muzycznymi. Format 3DMIDI – wprowadzony po raz pierwszy w X-Fi – umożliwia tworzenie i odtwarzanie muzyki wielokanałowej w formacie MIDI oraz remiksowanie starej 2-kanałowej treści MIDI dla potrzeb odtwarzania wielokanałowego.
Zarówno ISACT, jak i 3DMIDI, oferują „obojętny głośnikowo” format treści dla celu dostarczania do odbiorcy wielokanałowej muzyki i ścieżek dźwiękowych do gier. Umożliwiają one wierne odtwarzanie dźwięku przestrzennego na dowolnym systemie słuchawkowym lub głośnikowym, z możliwością interakcji ze strony użytkownika.
Technologie wzbogacania dźwięku przestrzennego CMSS-3D

Technologie wzbogacania dźwięku przestrzennego CMSS-3D firmy Creative mają za zadanie stawić czoła dominującemu wyzwaniu dzisiejszych systemów rozrywki: dopasowaniu formatu treści nagrania do formatu odtwarzania wykorzystywanego przez słuchacza. W wielu typowych scenariuszach odtwarzania dźwięku, założenia czynione na etapie produkcyjnym nie znajdują odzwierciedlenia po stronie odtwarzającej: system odtwarzający oferuje zbyt mało albo zbyt wiele kanałów, lub też nie są one wykorzystywane w sposób preferowany przez producenta (co często ma miejsce, kiedy odtwarzanie odbywa się przez słuchawki). Format źródłowy może być dwukanałowy lub wielokanałowy, o próbkowaniu 96 albo 192 kHz (DVD-Audio), lub też pomniejszony objętościowo za pomocą percepcyjnych koderów dźwięku. MP3, WMA lub Dolby Digital).
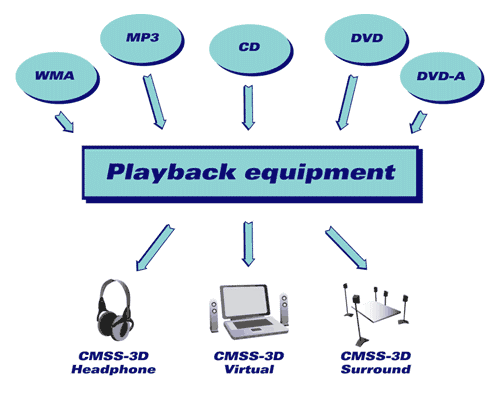
Firma Creative opracowała trzy własne algorytmy przetwarzania sygnału CMSS-3D, aby wyjść naprzeciw kwestii odtwarzania przez słuchawki, odtwarzania przez głośniki dwukanałowe oraz odtwarzania przez głośniki wielokanałowe (patrz: ilustracja 2). Każdy z algorytmów CMSS-3D ma za zadanie optymalizować doznanie odsłuchowe dla każdego formatu źródłowego, nawet kiedy jednocześnie odtwarzane są różne formaty z kilku źródeł (co może mieć miejsce na komputerze).
Celem wzbogacania dźwięku przestrzennego jest udoskonalenie doznań słuchacza poprzez próbę dopasowania sygnału dźwiękowego do systemu odtwarzającego, przy jednoczesnym odtwarzaniu wybranego obrazu dźwiękowego w jak najwierniejszy sposób. Dokładnie rzecz biorąc algorytmy CMSS-3D firmy Creative mają za zadanie spełniać następujące wymagania:
-po włączeniu wzbogacania intencje autora lub producenta nagrania powinny być zachowane. Chodzi tu szczególnie o barwę dźwięku, lokalizację oraz wzajemnej równowagi różnych instrumentów lub zdarzeń dźwiękowych składających się na kompozycję nagrania.
-po włączeniu wzbogacania nieświadomy słuchacz nie powinien być w stanie odczuć żadnej zmiany jakości nagrania. W szczególności algorytm nie powinien wprowadzać żadnych zakłócających lub nienaturalnych artefaktów mogących przeszkadzać słuchaczowi.
-wyłączenie wzbogacania powinno powodować zauważalne pogorszenie właściwości przestrzennych obrazu dźwiękowego. Proces wzbogacania dźwięku przestrzennego nie powinien jedynie dawać innej wersji pierwotnego nagrania: powinien on dawać poprawę, którą słuchacz przyswoi jako preferowaną metodę wykorzystywaną przy odtwarzaniu muzyki lub ścieżek dźwiękowych filmów.
W kolejnych dwóch paragrafach niniejszego artykułu przeanalizujemy nowatorskie techniki przetwarzania sygnału dźwiękowego, które firma Creative opracowała wychodząc naprzeciw wszystkim trzem wyzwaniom jednocześnie, dzięki czemu X-FI oraz pakiet technologii CMSS-3D zapewnią bezkompromisowe doznania odsłuchowe w każdej konfiguracji słuchawek lub głośników, przy każdym formacie treści.
CMSS-3DSurround: Miksowanie nagrań muzycznych na kilka kanałów

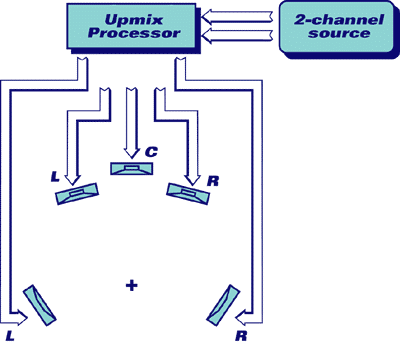
Technologia CMSS-3DSurround firmy Creative ma za zadanie „wymiksowywać” nagrania dwukanałowe do 4, 5, 6 lub 7 kanałów, w sposób przedstawiony na ilustracji 3. Kanały dźwięku dookólnego wykorzystywane są dla zapewnienia doznania bardziej opływającego odsłuchu, natomiast centralny głośnik przedni wykorzystywany jest to wytwarzania stereofonicznego obrazu frontalnego bardziej odpornego na ruchy słuchacza w bok od idealnej pozycji odsłuchowej („sweet spot”).
Wymiksowywanie źródła dwukanałowego do odtwarzania 5.1:
Tradycyjne sposoby podejścia do wymiksowywania wielokanałowego
Wiele spośród dzisiejszych wielokanałowych odbiorników kina domowego oraz niektóre samochodowe systemy dźwiękowe oferują jedną lub więcej opcji „wymiksowywania” nagrań dwukanałowych podczas odtwarzania przez wielokanałowe systemy głośnikowe, np. Dolby Prologic II, DTS Neo:6, SRS Circle Surround lub Lexicon Logic 7. Algorytmy te oparte są na popularnej zasadzie matrycowego dekodowania stereofonicznego, przedstawionej na ilustracji 4.
Ilustracja 4. Zasada konwencjonalnych matrycowych dekoderów stereofonicznych:
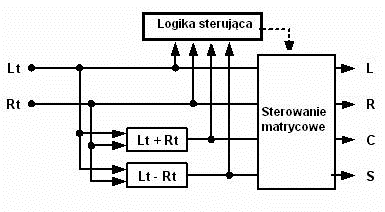
Technika stereofonicznego dekodowania matrycowego została pierwotnie wprowadzona w kinach w późnych latach 80-tych ubiegłego wieku i miała służyć do dekodowania nagrań z kodowanego matrycowo formatu dwukanałowego „(Lewy, Prawy)” z powrotem do formatu czterokanałowego „(Lewy, Środek, Prawy, Dookólny)”.
W kolejnej dekadzie technologia ta zawędrowała do domowych wielokanałowych systemów kina domowego. Nowsze matrycowe dekodery stereofoniczne zawierają modyfikacje służące do wytwarzania kilku oddzielnych kanałów dookólnych i zapewniają tryb „muzyczny” do wymiksowywania standardowych (niekodowanych) nagrań dwukanałowych.
W dekoderach tych, kanał przedni centralny wyprowadzany jest z sumy oryginalnego sygnału lewego i sygnału prawego, natomiast kanały dookólne (tylne) wyprowadzane są z ich różnicy. System „logiki sterującej” stale monitoruje i porównuje poziomy głośności sygnału lewego, prawego, centralnego i tylnego dla określenia kierunku dominacji w obrębie 360-stopniowego łuku dookoła słuchacza i wyregulowania proporcji oryginalnego sygnału lewego i sygnału prawego podawanymi na każdy z kanałów wyjściowych (kanały: lewy, centralny, prawy i dookólny).
Metoda ta jest skuteczna przy kodowaniu i dekodowaniu pojedynczego źródła dźwięku spanoramowanego w dowolnej pozycji na płaszczyźnie poziomej lub w chwilach, kiedy dialog lub jeden efekt dźwiękowy dominuje na ścieżce dźwiękowej. Jednak logiczny układ sterujący dekodera nie potrafi rozróżnić i wyłowić kilku jednoczesnych zdarzeń dźwiękowych spanoramowanych w różnych kierunkach. W nagraniach muzycznych często występują fragmenty, w których z miksu nie wyróżnia się żaden pojedynczy składnik dominujący. W takich fragmentach matrycowe dekodery stereofoniczne mogą rozmazywać i zwężać obraz stereofoniczny, dopuszczając do podawania umiejscowionych składników dźwiękowych na kanały dookólne, co może dalej zakłócać postrzegany obraz stereofoniczny i rozpraszać słuchacza, zwłaszcza w miejscach bliżej głośników tylnych. Z powodu niestacjonarnej natury sygnału muzycznego, układ logiczny sterowania matrycowego stale wprowadza do sygnału podawanego na głośniki wahania amplitudy, które mogą powodować niepożądane „pompowanie” na kanałach przednich lub dookólnych, albo też niestabilność obrazu przestrzennego.
Kolejnym ograniczeniem aktualnych matrycowych dekoderów stereofonicznych jest ich słaba wydajność przy materiale źródłowym kodowanym o małej szybkości transmisji danych (np. MP3 lub WMA): kanały dookólne często mają zniekształconą, „wibrującą” barwę dźwięku. Ów zakłócający artefakt jest bezpośrednią konsekwencją wyprowadzania kanałów dookólnych z różnicy pomiędzy pierwotnym sygnałem lewym a sygnałem prawym (operacja ta ujawnia artefakty wprowadzane przez proces kodowania MP3 lub WMA, które nie są słyszalne podczas normalnego odtwarzania bez wymiksowywania).
Podejście X-Fi do obróbki wymiksowywania
Firma Creative opracowała nową kategorie własnych (patent zgłoszony) algorytmów, aby wyjść naprzeciw wyzwaniom opisanym w poprzednim paragrafie. To nowe podejście odznacza się dwiema charakterystycznymi cechami, uzasadnionymi względami własności układów słuchowych oraz technik nagrywania wielokanałowego.
Przetwarzanie częstotliwości. Technologie CMSS-3D wykorzystują przetwarzanie częstotliwości, aby umożliwić rozróżnianie i umiejscawianie kilku jednoczesnych i odrębnych przestrzennie zdarzeń dźwiękowych w sposób analogiczny do układów słuchowych ludzi i innych ssaków. Ta właściwość naszego słuchu jest często określana jako „zjawisko koktajl-party” (zdolność koncentracji na jednej rozmowie pomiędzy kilkoma równoczesnymi rozmowami w danym pomieszczeniu). Podstawowym mechanizmem odpowiedzialnym za tę zdolność jest sygnałów z prawego i lewego ucha na dużej liczbie pasm częstotliwości. Ów proces słuchowy wykorzystuje dwa fakty: (a) mamy dwoje uszu i (b) zdarzenia dźwiękowe, których doznajemy są w dużym stopniu rozłączne (niepokrywające się) w obszarze częstotliwości. Bez analizy częstotliwości procesor wymiksowujący nie jest w stanie rozróżnić kilku zdarzeń dźwiękowych występujących jednocześnie, ponieważ wydaje się, że układają się one w jedno zdarzenie dźwiękowe.
oddzielanie dźwięków promieniowanych przez głośniki na pomieszczenie od dźwięków głównych. Istnieją dowody na to, że oprócz oddzielania kilku umiejscowionych zdarzeń dźwiękowych układ słuchowy potrafi oddzielać rozproszone przestrzennie (lub otaczające) elementy dźwiękowe, jak np. pogłos pomieszczenia, od elementów dźwiękowych toru bezpośredniego (czy też głównych). Zdolność tę obsługuje model przetwarzania słuchowego opisany w skrócie powyżej (w przypadku pól akustycznych rozproszonych przestrzennie, sygnał z prawego i sygnał z lewego ucha mają określone właściwości korelacyjne). Oddzielanie dźwięków otaczających od dźwięków głównych stanowi również podstawową zasadę technik nagrywania stereofonicznego i wielokanałowego. Na przykład w procesie miksowania nagrania wielościeżkowego dźwięki główne są umiejscawiane (lub panoramowane) oddzielnie w określonych kierunkach, natomiast dźwięki otaczające są zazwyczaj rozdzielane na kilka kanałów.
Proces CMSS-3DSurround
W odróżnieniu od poprzednich technologii wymiksowywania, CMSS-3DSurround rozkłada przetwarzany sygnał na elementy otaczające oraz główne i techniki wykorzystując częstotliwościowego przetwarzania sygnału uzyskuje dwie wyjątkowe funkcje (ilustracja 5):
Zasada algorytmu wymiksowującego CMSS-3DSurround
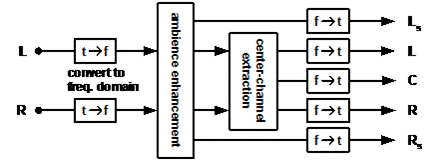
wydzielanie otoczenia.
Algorytm CMSS-3DSurround rozpoznaje elementy dźwiękowe otoczenia w nagraniu pierwotnym (np. pogłos pomieszczenia lub oklaski), wyprowadzając sygnały dźwięku dookólnego. Przywraca to naturalne odczucie zanurzenia oraz głębię na osi przód-tył, jednocześnie zachowując integralność czołowego obrazu stereofonicznego i pomijając drażniące artefakty powodowane przez „pompowanie” lub niepożądane „przesłuchy” umiejscowionych dźwięków w kanałach dookólnych. Kolejną ważną zaletą CMSS-3DSurround jest to, że nie wprowadza on zniekształceń do kanałów dookólnych w przypadku źródeł dźwięku kodowanych percepcyjnie, jak np. MP3 lub WMA.
wydzielanie kanału centralnego.
W odróżnieniu od tradycyjnych dekoderów stereofonicznych CMSS-3DSurround przeadresowuje dźwięki spanoramizowane centralnie do przedniego głośnika centralnego nie zmieniając pozostałych elementów obrazu stereofonicznego. Daje to rezultat w postaci zakotwiczenia umiejscowienia scentralizowanych głosów i instrumentów w nagraniach muzycznych lub też scentralizowanych dialogów w ścieżkach dźwiękowych filmów, przy zachowaniu szerokości, równowagi i barwy dźwięku pierwotnego obrazu stereofonicznego.
Poprzez połączenie tych dwu metod, CMSS3D-Surround obdarza nagrania dwukanałowe zaletami dźwięku dookólnego zachowując audofilskie doznania odsłuchowe:
-przywraca naturalne uczucie zanurzenia i głębię na osi przód-tył, nie wprowadzając przytłaczającej lub nienaturalnej przestrzeni (ponieważ algorytm wykorzystuje wyłącznie informacje przestrzenne obecne w pierwotnym nagraniu),
-powiększa tzw. „sweet spot” (optymalny punkt odsłuchu) w pokoju odsłuchowym (zakotwiczając dźwięki spanoramowane centralnie w kanale przednim centralnym i ograniczając przesłuchy dźwięków umiejscowionych w kanałach dookólnych),
-zachowuje równowagę, szerokość i barwę dźwięku pierwotnego obrazu stereofonicznego,
-nie wprowadza niestabilności do czołowego obrazu stereofonicznego w przestrzeni otaczającej,
-nie wprowadza zniekształceń do kanałów dookólnych nawet w przypadku źródeł dźwięku kodowanych percepcyjnie, jak np. MP3 lub WMA.
CMSS-3DHeadphone i CMSS-3DVirtual


Technologie CMSS-3DHeadphone i CMSS-3DVirtual firmy Creative mają za zadanie odtwarzać doznanie naturalnie brzmiącego odsłuchu wielokanałowego w słuchawkach lub dwóch głośnikach zarówno w przypadku formatów źródłowych wielokanałowych, jak i dwukanałowych. Te nowe technologie wirtualizacji trójwymiarowej dźwięku stanowią przełożenie rozległej wiedzy specjalistycznej firmy Creative w dziedzinie wirtualizacji dwuusznej i wirtualnego dźwięku dookólnego, co jest odzwierciedleniem wielu lat badań i rozwoju w laboratoriach IRCAM, UC Davis, Aureal, Sensaura oraz w Centrum Technologii Zaawansowanej firmy Creative.
Zasady i wyzwania technologii wirtualizacji trójwymiarowej dźwięku
Ogromna większość stereofonicznych nagrań dwukanałowych przeznaczonych jest do odtwarzania przez dwa głośniki umiejscowione przed słuchaczem. Natomiast przez słuchawki wydaje się, że dźwięki te umieszczone są wewnątrz głowy użytkownika na łuku łączącym uszy. Dźwięki spanoramowane centralnie wydają się być umiejscowione blisko czubka czaszki słuchacza, zamiast bezpośrednio przed nim, w pewnej odległości od głowy. Dźwięki spanoramizowane mocno w jedną ze stron „łechcą” ucho zamiast emanować z kierunku przedniego prawego lub przedniego lewego. W przypadku muzyki i ścieżek dźwiękowych wielokanałowych (jak np. DVD czy DVD-Audio), pogorszenie jest jeszcze bardziej drastyczne jeżeli pary kanałów przednich i tylnych są po prostu „stopione” ze sobą w jedną parę stereofoniczną, pozbawiając słuchacza możliwości słuchacza możliwości rozróżnienia przednich i tylnych zdarzeń dźwiękowych. Skutkiem tych zniekształceń przestrzennych jest nienaturalne i męczące doznanie odsłuchowe z poczuciem „zamknięcia”. Zmianie ulega również równowaga barwy dźwięku, wykazując brak tonów niskich i uwypuklenie tonów wysokich.
Bardziej zaawansowane rozwiązania przetwarzania sygnału, które mogłyby rozwiązać ów problem, wykorzystują technikę zwaną wirtualizacją dwuuszną. Proces ten stara się wytworzyć wrażenie, że nagranie jest faktycznie odsłuchiwane przez głośniki umiejscowione w spodziewanych pozycjach na płaszczyźnie poziomej przed i za lub z boku słuchacza, pomimo że odtwarzanie przebiega przez słuchawki.
Odbywa się to poprzez rekonstrukcję sygnałów dźwiękowych, które powinny być odbierane przez uszy słuchacza: każdy kanał źródłowy przepuszczany jest przez parę filtrów odpowiadających prawym i lewym przepustowościom związanymi z głową (HRTF), symulując „głośnik wirtualny”. Owe filtry HRTF muszą być starannie skonstruowane i zwykle wyprowadza się je z pomiarów za pomocą mikrofonów wetkniętych w kanaliki uszne ludzi lub makiet głów.
Technika ta może przynieść zauważalną poprawę odsłuchu przez zwykłe słuchawki. Jednak wrażenie odsłuchu przez prawdziwe głośniki było trudne do uzyskania. Przednie źródła dźwięku (kanały lewy, prawy lub centralny) nie są przekonywająco „uzewnętrznione” i „sfrontalizowane”. Za to wydaje się, że są one umiejscowione wewnątrz lub bardzo blisko głowy i podniesione (blisko czoła, niekiedy w stronę tyłu głowy). Boczne lub tylne źródła dźwięku wydają się być bliżej niż się spodziewamy, a źródła tylne może być trudno odróżnić od źródeł przednich. Niektóre algorytmy wirtualizacji mają również szkodliwy wpływ na ogólną barwę dźwięku nagrania.
Przy odtwarzaniu nagrań wielokanałowych przez parę głośników wyzwanie stanowi stworzenie wrażenia, że kanały dookólne są odtwarzane przez głośniki umiejscowione po bokach i z tyłu głowy słuchacza. Proces ten, określany często jako wirtualny dźwięk dookólny, zazwyczaj wykorzystuje dwuuszną scenę wirtualizacyjną podobną to tej, którą wykorzystuje się przy wzbogacaniu odtwarzania na słuchawkach (opisanym powyżej), a następnie proces redukcji przeników. Zadaniem redukcji przeników jest kompensowanie propagacji akustycznej pomiędzy głośnikiem a uchem (co wymaga redukowania sygnału „przenikającego”, który każde z uszu będzie odbierało z przeciwnego głośnika). Projektowanie skutecznego reduktora przeników wymaga starannej konstrukcji, umożliwiającej uzyskanie przekonywającego wrażenia wirtualnego dźwięku dookólnego przy uniknięciu niepożądanego zabarwienia barwy dźwięku źródła. Ponadto – z natury – ta technika odtwarzania jest skuteczna tylko w przypadku jednego słuchacza, znajdującego się dokładnie w „sweet spocie” z głową skierowaną w określonym kierunku (zwykle w połowie odległości pomiędzy dwoma głośnikami).
Proces CMSS-3DHeadphone
Technologia CMSS-3DHeadphone firmy Creative pomaga słuchaczowi zapomnieć, że ma na głowie słuchawki, zapewniając frapujące doznanie odsłuchu wielokanałowego przy każdej dwu- lub wielokanałowej treści dźwiękowej. Wynika to z połączenia trzech niepowtarzalnych składników:
-filtrów HRTF: Podstawę CMSS-3DHeadphone stanowi starannie dobrany zbiór danych HRTF wybranych z obszernej bazy danych pomiarów HRTF, przeprowadzonych w laboratoriach UC Davis, Aureal i Sensaura. w szeregu testów odsłuchowych, osoby badane wybierały zbiór danych zapewniający najlepszą jakość pod względem uzewnętrznienia, frontalizacji, rozróżniania na osi przód-tył oraz zachowania barwy dźwięku. zastosowano zaawansowane narzędzia obróbki końcowej, aby wyrównać i znormalizować surowe pomiary HRTF, a następnie przekształcić je w filtry HRTF bez naruszania dokładności modelu filtra.
-wczesnych odbić środowiskowych: algorytm CMSS-3DHeadphone eliminuje odczucie „zamknięcia”, kojarzone zwykle z odsłuchem na słuchawkach poprzez odtwarzanie naturalnych sygnałów przestrzennych przenoszonych poprzez odbicia środowiskowe wirtualnego pomieszczenia odsłuchowego, o starannie dostrojonych właściwościach akustycznych, zachowujących barwę materiału dźwiękowego. Proces ten ograniczony jest do symulacji „wczesnych” odbić w wirtualnym środowisku odsłuchowym, co zapewnia naturalne uczucie uzewnętrznienia i przestronności, nie zakłócając właściwości środowiskowych nagrania.
-wydzielania otoczenia: w przypadku dwukanałowych źródeł dźwięku, CMSS-3Dheadphone stosuje algorytm wydzielania otoczenia częstotliwościowego (wykorzystywany również w CMSS-3DSurround), aby zanurzyć słuchacza w przestrzeni pierwotnego nagrania. To niepowtarzalne udoskonalenie przydaje naturalnego odczucia głębi na osi przód-tył oraz odczucia opływania na słuchawkach, nie dodając żadnego sztucznego efektu pogłosowego do materiału pierwotnego.
Zalety CMSS-3DHeadphone można podsumować w następujący sposób:
-zachowanie barwy dźwięku,
-poprawa uzewnętrznienia, frontalizacji i rozróżniania na osi przód-tył,
-naturalne odczucie zanurzenia, zarówno w przypadku wielo- jak i dwukanałowych źródeł dźwięku,
-zmniejszenie zmęczenia przy słuchaniu.
Proces CMSS-3DVirtual
Technologia CMSS-3DVirtual daje słuchaczowi znajdującemu się w „sweet spocie” przekonywające złudzenie odsłuchu wielokanałowego przy dwóch tylko głośnikach, przy dowolnej dwu- lub wielokanałowej treści dźwiękowej. Łączy ona następujące składniki:
filtry HRTF: w celu symulacji wirtualnych głośników bocznych i tylnych systemu 5.1, 6.1 lub 7.1, CMSS-3Dvirtual wykorzystuje te same starannie skonstruowane i precyzyjnie wymodelowane filtry HRTF, co CMSS-3DHeadphone, symulacja odbić środowiskowych pomieszczenia wirtualnego nie jest konieczna podczas odsłuchu z głośników, ponieważ odtwarzanie jest naturalnie uzewnętrzniane,
reduktor przeniku: reduktor przeniku obecny w CMSS-3DVirtual został specjalnie przekonstruowany, aby zapewniać najbardziej przekonywające wrażenie głośnika wirtualnego bez naruszania barwy brzmieniowej nagrania, 1 użytkownik może skalibrować dookólny proces wirtualny dla uzyskania optymalnego efektu nawet przy niestandardowym usytuowaniu głośników, wprowadzając odległość i pozycję kątową każdego z głośników do panelu sterowania ustawień THX,
wydzielanie otoczenia, w przypadku dwukanałowych źródeł dźwięku głośniki wirtualnego dźwięku dookólnego wykorzystywane są do odtwarzania naturalnego opływającego otoczenia na podstawie informacji przestrzennych obecnych już w nagraniu, jest to kolejne zastosowanie wyjątkowego algorytmu wydzielania otoczenia częstotliwościowego, stosowanego również w przypadku CMSS-3DSurround i CMSS-3DHeadphone.
Zalety CMSS-3DVirtual można podsumować w następujący sposób:
-zachowanie barwy dźwięku,
-przekonywające umiejscowienie bocznych i tylnych głośników wirtualnych,
-naturalne odczucie zanurzenia, zarówno w przypadku wielo- jak i dwukanałowych źródeł dźwięku,
-kalibracja zgodna z usytuowaniem głośników w stosunku do słuchacza.
CMSS-3DInteractive

CMSS-3DInteractive to nowa generacja trójwymiarowej technologii dźwięku Creative, w którą wyposażona jest platforma X-Fi. Opiera się ona na możliwościach pozycyjnego silnika dźwięku Audigy: wydajnym trójwymiarowym panoramicznym schemacie obsługującym dużą liczbę źródeł dźwięku trójwymiarowego, ścisłej integracji z silnikiem środowiska dźwiękowego EAX i kątowej kalibracji umożliwiającej dokładną reprodukcję przestrzenną przy wykorzystaniu niestandardowych układów głośników. Jedną z głównych dodatkowych innowacji w CMSS-3DInteractive jest silnik dwuusznego przetwarzania, który umożliwia dokładne tworzenie pozycyjnego dźwięku dla każdego jego źródła, przy zachowaniu wydajności wymaganej do obsługi dotąd nieosiągalnej liczby równoczesnych źródeł.
Dzięki własności intelektualnej Creative i mocy obliczeniowej platformy X-Fi, CMSS-3DInteractvie zapewnia niespotykaną wydajność w tworzeniu trójwymiarowego dźwięku pozycyjnego za pomocą słuchawek i zestawów składających się z dwóch lub więcej głośników:
-umożliwia tworzenie setek równoczesnych źródeł dźwięku,
-bezbłędnie tworzy trójwymiarowy dźwięk pozycyjny w słuchawkach i przez głośniki,
-obsługuje MacroFX: efekt realistycznej odległości dla bliskich źródeł,
-kątowa kalibracja umożliwiająca dokładne pozycjonowanie przy użyciu niestandardowych układów głośników,
-ścisła integracja z silnikiem środowiska dźwiękowego EAX dająca perfekcyjną zgodność z EAX.
W następnych paragrafach przyjrzymy się wyzwaniom jakie towarzyszyły projektowaniu i wprowadzaniu interaktywnych silników trójwymiarowego dźwięku pozycyjnego za pomocą słuchawek i głośników, a także jak wyzwania te mają się na tle CMSS-3DInteractive.
Interaktywny trójwymiarowy dźwięk w słuchawkach
Tworzenie trójwymiarowego dźwięku pozycyjnego wymaga silnika przetwarzającego sygnał, zdolnego do pozycjonowania wielu źródeł dźwięku w odrębnych i dynamicznych pozycjach wokół słuchacza. Aby stworzyć taką iluzję za pomocą słuchawek, konieczne jest użycie pary filtrów dla każdego źródła, tak aby zrekonstruować sygnały akustyczne, które zostałyby zarejestrowane przez lewe i prawe ucho w świecie rzeczywistym.
Zasada dwuusznego trójwymiarowego panoramowania dla jednego źródła dźwięku:

Jak pokazuje powyższa ilustracja, proces ten można podzielić na 3 części:
ITD (Interaural Time Difference) – różnica czasowa pomiędzy uszami. ITD to różnica w czasie zarejestrowania dźwięku przez uszy. Jest to główny sygnał konieczny do postrzegania stopnia lateralizacji czyli lokalizowania źródła dźwięku po lewej lub prawej stronie słuchacza.
ILD (Interaural Level Difference). ILD to różnica w natężeniu dźwięku pomiędzy sygnałami docierającymi do uszu słuchacza ze źródła znajdującego się po jednej jego stronie. Zwiększa się ona znacząco gdy źródło zbliża się do głowy na mniej niż 1 metr.
Filtr HRTF. Jest to najbardziej złożony efekt, jako że rejestruje wszystkie widmowe transformacje, którym zostaje poddany dźwięk zanim dotrze do kanału usznego (włączając akustyczną dyfrakcję wokół głowy oraz odbicia od ramion i krawędzi małżowiny usznej).
Z racji tego, że każde ze źródeł dźwięku (również ruchomego) może być usytuowane w dowolnym miejscu trójwymiarowej przestrzeni, aspekty przetwarzania wymagają przestrzennej interpolacji w czasie rzeczywistym, co składa się na złożoność systemu. Podczas gdy ITD I ILD są relatywnie proste do modelowania i reprodukcji, zastosowanie dokładnych filtrów HRTF oznacza wysokie zapotrzebowanie na moc obliczeniową dla danego źródła. Z tego też powodu trójwymiarowe silniki dźwięku pozycyjnego, takie jak karty dźwiękowe PC, były ograniczane przez liczbę trójwymiarowych źródeł i dokładność dźwięku.
Aby przezwyciężyć te ograniczenia, CMSS-3DInteractive platformy X-Fi wprowadza nowatorskie, wyjątkowe metody efektywnego i dokładnego tworzenia dwuusznej trójwymiarowej panoramy (patent w toku). Tak jak Audigy, X-Fi korzysta z ustalonego zasobu ukierunkowanych filtrów HRTF, który jest dzielony pomiędzy wszystkie źródła trójwymiarowe, a nie z par filtrów HRTF dla każdego źródła. Jednakże, silnik CMSS-3DInteractive zachowuje poprawne ITD i ILD dla każdego źródła w każdej pozycji.
Dzięki silnikowi dwuusznego przetwarzania, CMSS-3DInteractive dostarcza następujących korzyści interaktywnym aplikacjom, takim jak gry, odtwarzającym dźwięk trójwymiarowy za pomocą słuchawek:
Bezkompromisowa dokładność filtra HRTF, bez względu na liczbę równoczesnych źródeł dźwięku trójwymiarowego. Wszystkie źródła dźwięku trójwymiarowego korzystają z tych samych, dokładnych filtrów HRTF, które są włączone w proces CMSS-3DHeadphone.
Obsługa technologii MacroFX Sensaury, która oddaje efekt naturalnej odległości od źródeł znajdujących się blisko głowy.
Wyraźne odwzorowywanie przestrzenne z poprawionym rozróżnieniem pomiędzy przodem i tyłem i bardziej przekonywającymi efektami dla źródeł umieszczonych ponad lub poniżej płaszczyzny horyzontu.
Płynna interpolacja przestrzenna pomiędzy pozycjami, bez żadnych zjawisk takich jak uciążliwe zmiany barwy dźwięku podczas ruchu jego źródła.
Interaktywny dźwięk 3D przez głośniki
Wszystkie wyżej opisane korzyści dla CMSS-3DInteractive obecne przy korzystaniu ze słuchawek, odnoszą się także do konfiguracji odtwarzania za pomocą głośników wyposażonych w SMSS-3DVirtual. Oznacza to, że wszystkie źródła dźwięku 3D korzystają z poprawionego przetwarzania wirtualnego, przestrzennego dźwięku, który pozwala określić boczną i tylną lokalizację za pomocą głośników, zachowując barwę dźwięku.
W przypadku głośników 4.0, CMSS-3DVirtual wprowadza dodatkowo kasowanie przesłuchu dla tylnej pary głośników (tak jak w SoundBlaster Live! i Audigy, a także w technologii Sensaury MultiDrive. Sprawia to, że wydajność lokalizowania rośnie i staje się bardziej stabilna nie tylko dla tylnych źródeł, ale także dla bocznych lub podniesionych, nawet jeśli słuchacz przesuwa się z punktu pierwotnego.
Jeśli chodzi o głośniki 5.1, 6,1 lub 7,1, funkcje wielokanałowego panoramowania w silniku CMSS-3DInteractive zostały tak zaprojektowane, aby zapewnić sprawną lokalizację, dokładne pozycjonowanie i płynne poruszanie się po większej powierzchni (uwzględniając wielu słuchaczy w typowej konfiguracji kina domowego).
EAX w X-Fi: Wszechstronna architektura przetwarzania dźwięku 3D i efektów
W tej części przyjrzymy się architekturze przetwarzania dźwięku X-Fi, a także przybliżymy wyjątkowe cechy, które sprawiają, że X-Fi to wszechstronny silnik dźwięku 3D przeznaczony do gier, tworzenia muzyki oraz odtwarzania filmów i muzyki. Architektura przetwarzania dźwięku określa topologię przetwarzania i mieszania sygnału przez platformę X-Fi. Już na samym początku postanowiono, że inżynierowie zajmujący się sprzętem i oprogramowaniem określą wymagania konieczne do przetwarzania dźwięku, zapewniając tym samym, że X-Fi będzie obsługiwać szeroką gamę aplikacji i standardów, równocześnie oferując elastyczność konieczną do optymalizowania użycia sprzętu w zależności od użytkownika. Architektura X-Fi posiada szkielet modularny zaprojektowany, aby maksymalizować ponowne użycie algorytmów DSP i minimalizować czas wprowadzania na rynek rozszerzeń dla platformy.
Projekt spełnia następujące pierwotne założenia:
Obsługuje obecne i mające pojawić się standardy multimedialne: API obsługiwane w tej chwili przez Creative takie jak Open AL, Microsoft DirectSound, GameCoda oraz EAX, a także pojawiające się standardy takie jak format opisu scenerii otoczenia wykorzystany w standardzie MPEG-4, przy określaniu którego Creative udzielał pomocy.
Obejmuje obecne i przewidywane scenariusze, w skład których wchodzą następujące aplikacje: gry (interaktywny dźwięk 3D), rozrywka (odtwarzanie muzyki i filmów) i tworzenie muzyki (nagrywanie oraz tworzenie muzyki i ścieżek dźwiękowych).
Podkreśla najważniejsze funkcje korzystne dla użytkownika: modularna budowa pozwala na wyjęcie tych modułów, które nie są akurat dostosowane do potrzeb użytkownika i zamianę ich na elementy zoptymalizowane pod kątem wybranej aplikacji i konfiguracji.
Podstawowe wymagania muzycznej stacji roboczej
Aby przyjrzeć się założeniom architektury X-Fi, zacznijmy od podstawowych wymagań aplikacji służących do tworzenia muzyki. W przypadku muzycznych stacji roboczych, detale dotyczące topologii miksowania przedstawione są za pomocą parametrów sterowania miksowaniem. Prezentuje to ilustracja 8, która przedstawia panel miksera X-Fi. Podobnie jak w studyjnych konsolach do miksowania i stacjach roboczych służących do obróbki dźwięku, każdy z pionowych paneli zawiera parametry charakterystyczne dla odpowiedniego źródła, takie jak głośność, panoramowanie, efekty wsadowe i pomocnicze. Prawa strona przedstawia panel sterowania wspólny dla wszystkich źródeł. Pozwala on zmieniać parametry efektu pomocniczego i globalnego.
Zrzut ekranu konsoli X-Fi
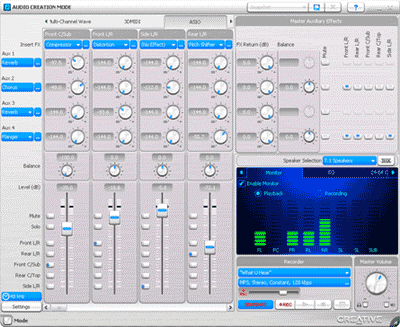
Ilustracja przedstawia topologię przetwarzania efektu, tzn. gdzie umieszczone są różnego rodzaju efekty w łańcuchu przetwarzania i gdzie zastosowane zostały podstawowe panele widoczne dla użytkownika (z racji tego, że topologia jest identyczna dla wszystkich źródeł, przedstawione jest tylko jedno źródło). Efekty wsadowe zastosowane zostały w przypadku indywidualnych źródeł, podczas gdy efekty globalne dostępne są w ostatnim etapie na głównej magistrali. Efekt pomocniczy jest wspólny dla wszystkich źródeł, ale dostępny jest na szynie równoległej, która otrzymuje różne sygnały z każdego źródła. Następnie sygnał wyjściowy efektu pomocniczego dodany zostaje do szyny głównej, tak jak dodatkowe źródło.
Uniwersalny silnik renderowania dźwięku
Architektura przetwarzania dźwięku X-Fi może być postrzegana jako rozszerzenie topologii miksera. Przedstawia to ilustracja 10, gdzie łańcuch przetwarzania został pokazany od prawej do lewej i podzielony na trzy główne etapy: „przed przetwarzaniem”, miksowanie trójwymiarowe i „po przetwarzaniu”. Dodatkowo, na każdym z etapów dostępne są funkcje wspomagające zaawansowane gry, tworzenie muzyki i aplikacje służące rozrywce. Przykładami takich funkcji są wzbogacenia dźwięku przestrzennego CMSS-3D, interaktywny trójwymiarowy dźwięk pozycyjny, wielokanałowe miksowanie i efekty EAX. W przypadku tej modularnej budowy, każda funkcja przetwarzania może być wywołana lub zamieniona w zależności od potrzeb określonej aplikacji lub użytkownika.
Architektura przetwarzania X-Fi traktuje wszystkie źródła tak samo, bez względu na ich pochodzenie (czy to pamięć komputera czy zewnętrzne źródła takie jak mikrofon) i format lub jakość próbkowania. X-Fi może stosować ten sam zestaw efektów i algorytmów w stosunku do wszystkich źródeł 3D (efekty dźwiękowe w grach), MIDI, zewnętrznych wejść lub strumieni dekodowanych z dowolnego formatu np.: mp3, WMA, DVD Video lub DVD Audio.
Faza „przed przetwarzaniem” obejmuje możliwość zastosowania efektu wsadowego na pojedynczych źródłach, ale może także zostać poszerzona, jeśli to konieczne, i zmieniona w elastyczną sieć efektów wielokanałowych umożliwiającą miksowanie wstępne lub matrycowanie wielu źródeł. Sygnałem wyjściowym fazy „przed przetwarzaniem” jest zbiór wirtualnych źródeł dźwięku trójwymiarowego, które następnie są uprzestrzenniane podczas etapu miksowania 3D, aby tworzyć reprodukowany dźwięk.
Ogólny diagram architektury renderowania przez X-Fi;

Rdzeniem tej architektury jest mikser 3D. Podczas gdy zdolność ta była dotąd zarezerwowana dla źródeł 3D w grach, X-Fi może przetwarzać dowolne źródło jako źródło dźwięku trójwymiarowego, włączając w to np.: instrumenty MIDI lub muzykę wielokanałową i ścieżki dźwiękowe. Elastyczność pozwala platformie wspomagać nowe cechy EAX i nowe standardy takie jak 3DMIDI, ISACT, a także zaawansowane funkcje tworzenia dźwięku przestrzennego wchodzące w skład standardu MPEG-4.
Oprócz takich efektów jak panoramowanie i efekty pomocnicze oferowane przez standardową muzyczną stację roboczą, X-Fi obsługuje zaawansowane funkcje wymagane w grach 3D, takie jak efekt Dopplera i wielokanałowość oraz panoramowanie 3D (CMSS-3DIneractive) oraz takie cechy EAX jak okluzja, przeszkoda, wielośrodowiskowe i środowiskowe panoramowanie. Ze względu na elastyczność architektury X-Fi, funkcje te mogą być wykorzystywane w tworzeniu muzyki i rozrywce. X-Fi jest nie tylko najmocniejszą i najbardziej wydajną dostępną platformą do gier, ale także wyszukaną, wielokanałową muzyczną stacją roboczą.
Z kolei faza „po przetwarzaniu” dostarcza zbiór zaawansowanych technologii wzbogacających odtwarzanie, które optymalizują doznania słuchowe i dostosowują je do subiektywnych preferencji użytkownika. Częścią tej fazy są procesy wzbogacenia dźwięku przestrzennego (CMSS-3DSurround, CMSS-3DHeadphone, CMSS-3DVirtual), kalibracja głośników i wielokanałowy korektor graficzny.
EAX ADVANCED HD 5.0 – zaawansowany sprzęt 5.0 EAX
Dzięki uaktualnieniu drivera EAX 4.0, wydanemu w listopadzie 2003, Audigy stało się pierwszą interaktywną platformą 3D, która obsługiwała wielośrodowiskowe renderowanie. Zwiększyło to znacząco realizm wirtualnych światów 3D: słuchacz jest w stanie odróżnić akustyczną charakterystykę przyległych pomieszczeń lub przestrzeni w wirtualnym świecie, a także słyszeć naturalny, przestrzenny efekt towarzyszący poruszaniu się po pomieszczeniu lub wychodzeniu z niego.
Dzięki możliwościom przetwarzania efektu wielośrodowiskowego i poszerzonemu efektowi EAX 4.0, API EAX 5.0 udostępnia następujące nowe opcje w grach i tworzeniu muzyki:
EAX FlexiFX
EAX 5.0 zapewnia producentom gier i twórcom muzyki jeszcze większą elastyczność tworzenia efektów. Do każdego z czterech slotów efektów może zostać wgrany dowolny efekt EAX. X-Fi EAX 5.0 będzie przetwarzać jednocześnie do czterech efektów pogłosu i 128 równoczesnych źródeł dźwięku 3D. Dzięki temu cztery pomocnicze szyny efektów mogą być aktywne na wszystkich źródłach, a także możliwe będzie nakładanie efektów na sygnały zarówno dwu jak i wielokanałowe. Programista może także wybrać miksowanie dwóch kanałów źródłowych, aby stworzyć wielokanałowe tło lub otaczającą przestrzeń w grze, lub miksowanie sygnału wyjściowego slotu dwukanałowego, aby stworzyć np.: efekt chorus.
EAX PurePath
EAX 5.0 oferuje pełną kontrolę nad sygnałami wielokanałowymi i kierowaniem ich do wybranych głośników. Umożliwia to określenie udziału każdego ze źródeł w kanale LFE (Low-Frequency Enhancement), i przesłanie dialogów do głośnika centralnego lub nawet programowanie wspomaganych sprzętowo wielokanałowych algorytmów panoramowania.
EAX MacroFX
EAX 5.0 zapewnia kontrolę nad efektami bliskości, czyli symulacją źródeł dźwięku znajdujących się bardzo blisko słuchacza.
Environment Occlusion
Funkcja ta ulepsza tworzenie dźwięku w wielu środowiskach pozwalając na realistyczna symulację efektu tłumienia będącego wynikiem wygłuszania przez ścianę dźwięku pochodzącego z innego pomieszczenia.
Pomimo że daje to cenne rozszerzenia możliwości, które dostępne będą w grach EAX, API EAX 5.0 w niewielkim stopniu wykorzystuje możliwości X-Fi i pozostawia sporą część sprzętu nietkniętą. Przyszłe rozszerzenia umożliwione przez architekturę przetwarzania dźwięku X-Fi obejmują efekty wsadowe, dyskretne odbicia środowiskowe, a także większą liczbę źródeł 3D.
EAX Voice – głos EAX
Oprócz wielu nowych możliwości jakie posiada API EAX 5.0, silnik EAX X-Fi niesie ze sobą nowy poziom realizmu w przetwarzaniu głosu w grach, wprowadzając nowe sterowanie Microphone Environment FX. Sterowanie pozwala użytkownikowi podłączyć sygnał mikrofonu do silnika przetwarzania środowiskowego EAX i słyszeć swój głos w środowisku gry.
Ta wyjątkowa cecha pozwala w znaczący sposób podnieść poziom „zanurzenia” gracza w wirtualnym, trójwymiarowym świecie. Podczas odkrywania poziomu gry i równoczesnego korzystania z mikrofonu, gracz często dostrzeże zaskakujące bogactwo akustyczne wirtualnego środowiska, włącznie z efektami pogłosu, które mogłyby pozostać niezauważone z racji tego, że nie są tak dokładnie wyeksponowane przez inne źródła obecne w wirtualnym świecie gry.
Microphone Environment FX, w które wyposażony jest X-Fi, jest kompatybilne ze wszystkimi grami EAX. Jeżeli chodzi o gry, które obsługują EAX 3.0 lub wcześniejszy, wystarczy, że korzystają one z silnika pogłosu EAX do generowania środowiska słuchacza, co jest powszechnie stosowaną praktyką. W przypadku gier EAX 4.0 i 5.0, obsługujących wiele równoczesnych procesów środowiskowego pogłosu, sygnał mikrofonu zostanie automatycznie przekierowany do podstawowego środowiska, które modeluje pomieszczenie lub przestrzeń, i w którym w danej chwili znajduje się słuchacz.
Wrażenia z używania EAX Voice przykuwają uwagę szczególnie w przypadku gier wieloosobowych, które obsługują efekt przestrzenności głosów należących do oddalonych graczy w taki sposób, że każdy z oddalonych głosów wydaje się dochodzić z miejsca, w którym znajduje się jego wirtualny odpowiednik. W takich grach technologia EAX wzmacnia poczucie „teleobecności”, pozwalając użytkownikowi słyszeć każdy z oddalonych głosów graczy w obrębie akustycznego środowiska gry. Jeżeli chodzi o głos gracza, Microphone Environment FX zapewnia takie same korzyści, tworząc realistyczną symulację środowiska trybu wieloosobowego.
Konkluzje
Przez ostatnie parę lat niespotykane połączenie własności intelektualnych i wiodących badań, sprawiło, że Creative opracował pełny zestaw technologii dźwięku EAX i CMSS-3D, mających na celu zapewnienie najlepszego przestrzennego dźwięku oraz wielokanałowego, akustycznego doznania, a także wydajności i możliwości przetwarzania dostępnych dla wszystkich aplikacji dźwięku cyfrowego:
-w rozrywce, grach i tworzeniu muzyki,
-za pomocą słuchawek, dwu i wielokanałowych głośników,
-na komputerach stacjonarnych i notebookach, systemach kina domowego i przenośnych urządzeniach.
Połączenie tych technologii z potężnymi możliwościami przetwarzania stworzyło niepowtarzalną platformę do tworzenia dźwięku 3D, która obsługuje różne formaty odtwarzania za pomocą głośników i słuchawek oraz dostarcza unikalnych korzyści każdej aplikacji dźwiękowej. Oto następujące korzyści:
Wyjątkowe technologie ulepszające dźwięk przestrzenny w wielokanałowym miksowaniu oraz wirtualizacji muzyki i filmów, obsługujące próbki 24-bitowe przy częstotliwościach próbkowania 96/192 kHz na wszystkich źródłach dźwięku o zaawansowanej rozdzielczości,
Elastyczny i spełniający wymagania przyszłości silnik zaprojektowany dla interaktywnego dźwięku 3D, oferujący najwyższą jakość trójwymiarowego dźwięku pozycyjnego, obsługujący do 128 źródeł 3D i wspierający każdą sprzętową topologię przetwarzania/miksowania,
Potężna muzyczna stacja robocza przeznaczona do wielokanałowego tworzenia muzyki w dowolnym formacie nagrywania włącznie z nowym standardem Creative, zaprojektowanym do redagowania wielokanałowego MIDI i odtwarzania.
Bez względu na aplikacje (gry, muzyka, odtwarzanie filmów czy tworzenie muzyki), platforma X-Fi dostarcza nowy poziom funkcjonalności, jakości dźwięku, „zanurzenia” w dźwięku wielokanałowym i realizmu 3D na komputerze PC.
Dr. Jean-Marc Jot
kierownik naukowców dźwięku 3D, Ośrodka Technologii Zaawansowanej firmy Creative